 If you’ve been working long enough in IT, you know that disasters do happen. It may not be a tornado or thunder blowing up your datacenter, but something will happen sooner or later which will require you to execute on that DR plan which has been gathering dust on your desk.
If you’ve been working long enough in IT, you know that disasters do happen. It may not be a tornado or thunder blowing up your datacenter, but something will happen sooner or later which will require you to execute on that DR plan which has been gathering dust on your desk.
Whether Disaster Recovery (DR) plans are executed planned or unplanned, there are always things that go wrong, no matter how prepared you think you are. There are simply too many moving parts and variables: will the network failover properly? Will I have enough compute capacity at my recovery site to start everything? How will I recover my data? Will I have knowledgeable staff trained on the failover procedures? How will I failback once the primary site has been recovered?
One thing is for sure: things have changed. Whereas reliance on tape backups is still very much a thing, technology has evolved and infrastructure has gotten seemingly simpler.
Virtualization has helped overcome hardware compatibility issues. Networking has evolved and made IP reconfiguration a thing of the past. Storage replication has become synchronous enabling zero recovery point objective (RPO). Software defined infrastructure has enabled end to end automation enabling near zero recovery time objective (RTO). Metro clusters are invading datacenters enabling active-active configurations.
Still, all those new shiny technologies require skills and deep integration. Compatibility matrixes are still fairly complex and evolving faster than you can document it.
Then there is hyper-convergence. Merging storage and compute into a single software-defined solution most definitely makes things easier because you don’t have to figure out those things separately from one another. If in addition you have a nice intuitive interface to manage it which itself is always highly available, then you’ve hit the jackpot. You see where I’m going with this…
Nutanix Xtreme Computing Platform (XCP) has had built-in asynchronous and synchronous replication for a while now and this series will explore those options in more details, specifically on the VMware vSphere virtualization platform.
In part 1, we will cover the basic features of data replication in Nutanix Acropolis Base Software (formerly known as Nutanix Operating System or NOS). We will explain what Async DR is and how to set it up. We will also explain what Metro Availability is and how to set it up (with a bonus Powershell script to assist with some of the more tedious vSphere DRS configuration tasks) and finally, we’ll cover Sync DR as well.
In part 2, we will look at how to do planned failovers and failbacks for Async DR, Sync DR and Metro Availability.
Finally, in part 3, we will look at how to execute unplanned DR with Async DR, Sync DR and Metro Availability, including how to failback once your failed site has been recovered.
Comparing protection domain types
All right, enough with the chitchat and on with the replication features available in Nutanix.
Nutanix with vSphere as a virtualization platform currently has several options available for data replication: Async DR, Sync DR and Metro Availability. Think of it as asynchronous vs synchronous with some nuances.
First, some Nutanix specific terminology: data protection is implemented using what we call “Protection Domains”. A protection domain (PD) can be of either type Async DR or Metro Availability (Sync DR is configured in the same place as Metro Availability).
When a PD is of type Async DR, you can protect individual VMs and you can replicate every hour as the smallest replication interval.
With Async DR PDs, you normally failover those VMs to a different vSphere cluster which itself lives on a different Nutanix cluster (see fig. 1 below).
Async DR essentially means that you will snapshot your VMs locally, then replicate those snapshots to that other Nutanix cluster. You define the replication interval and the retention policy. You can also specify multiple replication targets, which are known as “Remote Sites”. That remote cluster may or may not have the same VLANs and subnets as your original site, so Async DR can be complemented with VMware Site Recovery Manager to automate the failover and failback and VM network reconfiguration.

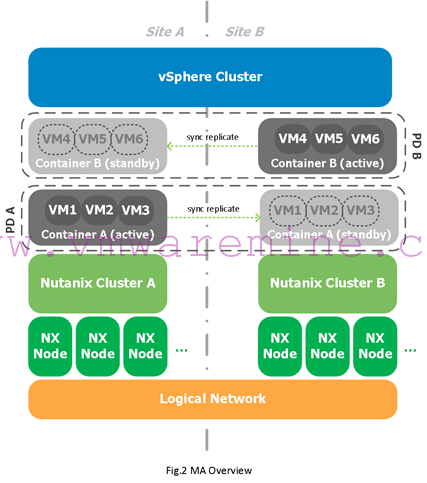
With a metro availability PD, you replicate an entire container (what is seen as an NFS datastore on your ESXi hosts) to another Nutanix cluster, but nodes (aka servers or hosts) which make up both of those replicating Nutanix clusters are part of the same compute cluster (one single HA/DRS cluster; see fig. 2 above). That means the VLANs and subnets are stretched across both locations and VMware HA is used to automatically restart VMs on the remaining site in case of a disaster. The requirement for Metro Availability (MA) is to have a maximum of 5 ms latency on average between all the Nutanix nodes on the network.
It is important to understand that as shown in Fig.2 above, there are then two copies of the container, one in each Nutanix cluster. One copy is “Active” meaning it services read and write I/Os while the other is in “Standby”, meaning it is read-only and does not service ANY I/O request (yes, even read I/O requests will go to the Active container).
That means in normal conditions, you don’t really want virtual machines which have their storage in the active container in site A to be running on hosts in site B. While that is technically possible, it will potentially be bad for your network link between both sites. That’s why Nutanix recommends using DRS affinity rules to keep virtual machines local to the hosts holding the active copy of the container (more on that later).
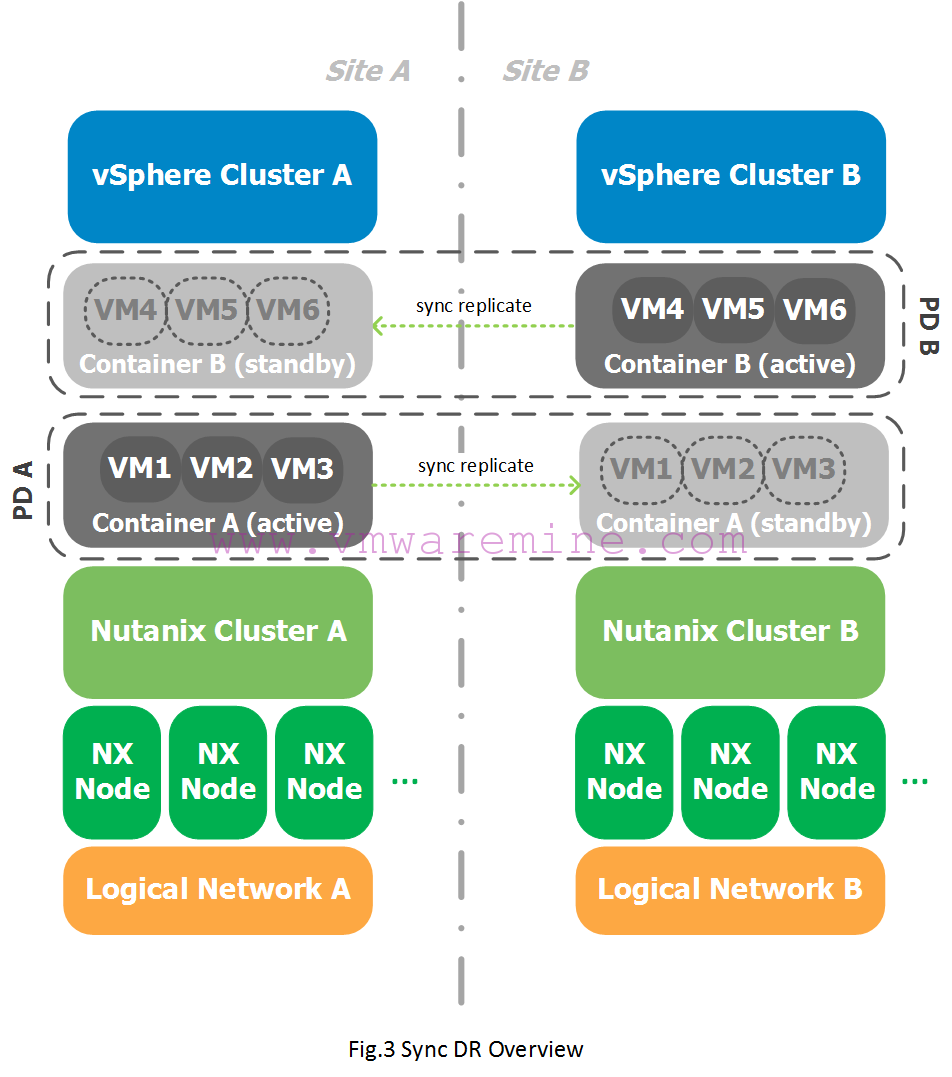
Note that the Prism user interface (UI) does not distinguish between Metro Availability and Sync DR, so don’t look for the Sync DR option, it’s not there. Essentially, if you are running two separate vSphere Clusters, or if you’re running on Hyper-V and you add a Metro Availability Protection Domain, it is by nature a Sync DR, even though it is called Metro Availability in the UI. I know, this is a bit confusing, but hopefully looking at Fig. 3 above will clear this up for you.
The table below highlights the main differences between Async DR, Sync DR and MA protection domains.
|
Async DR |
Metro Availability |
Sync DR |
|||
| Quantity of Nutanix Clusters |
2 |
2 |
2 |
||
| Quantity of vSphere Clusters |
2 |
1 |
2 |
||
| Stretched VLANs |
No1 |
Yes |
No1 |
||
| Protected Entity |
Virtual Machine |
Container |
Container |
||
| Targets |
One to one, one to many, many to one |
One to one |
One to one |
||
| Type of Replication |
Asynchronous |
Synchronous |
Synchronous |
||
| RPO |
>= 1 hour |
0 |
0 |
||
| RTO |
Minutes to hours2 |
Minutes |
Minutes to hours2 |
||
| Network Requirement |
N/A |
5 ms latency |
5 ms latency |
||
| Supported Hypervisors3 |
vSphere, Hyper-V, Acropolis |
vSphere |
vSphere, Hyper-V |
||
1: While stretched VLANs are not required, they will shorten your RTO by making network reconfiguration unnecessary. If you do not have stretched VLANs, you can use VMware Site Recovery Manager with Async DR as Nutanix has a Storage Replication Agent (SRA) available, but you cannot use SRM with Sync DR.
2: This is mostly depending on whether network reconfiguration is required.
3: As of Acropolis Software version 4.5.0.2 (October 2015)
With all that being said, does this mean that you absolutely need two vSphere clusters to do Async DR between two Nutanix clusters? Absolutely not. You could very well have a metro cluster in which you choose to have two type of VMs: those which are protected by MA with an RPO of 0 and those which are protected by Async DR with an RPO of 1 hour or more. I’m just giving you what are typical scenarios.
The only strict rule is that it can’t be really called a Metro Availability setup if you have more than one compute cluster, because then it is Sync DR, not MA. And remember that MA is currently only supported on VMware vSphere.
Configuring Async DR
Configuring Async DR is very straightforward:
- Decide which containers are going to be used at the source and remote site for replicating the snapshots
- Create the remote site at each end and define a container/vstore mapping based on what you determined in step 1
- On the source cluster, add a Protection Domain of type Async DR, select the virtual machine you want to protect and if you want to regroup them in consistency groups (more on that later)
- Define a schedule for your Async DR PD, a target remote site, and a retention policy for both local and remote targets
- That’s it!
So, what are consistency groups? Consistency Groups (CG) are a logical way for you to define a group of VMs which will have snapshots taken at the exact same moment (as opposed to sequentially). This may be important if you have a multi-tier application and you want to make sure the snapshot data is consistent.
When you run on vSphere, you also have the option on enabling VSS consistent snapshots which will use Microsoft Volume Shadow Services thru the VMware tools to notify the OS that a storage snapshot is about to occur and that pending I/Os should be committed to disk so that the data is not just crash consistent.
So, to include screenshots (which visual people like me enjoy since seeing is believing), I will set this up in my lab.
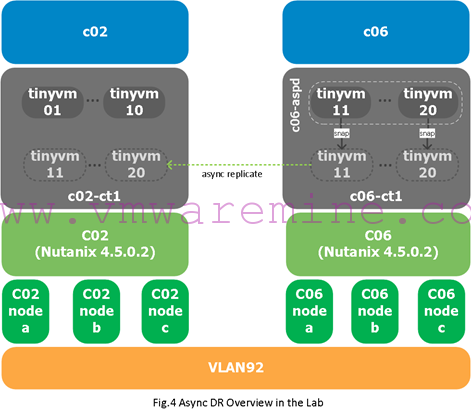
My setup is as follows:
- I have two Nutanix clusters: c02 and c06. Each Nutanix cluster has three nodes (c02nodea, c02nodeb and c02nodec for c02, and c06nodea, c06nodeb and c06nodec for c06).
- All hosts are running vSphere 5.5 and Nutanix Acropolis Software 4.5.0.2
- The VMs use VLAN92 which is stretched (so no need for IP reconfiguration when failing over VMs).
- C02 hosts make up the c02 compute cluster. It uses the container/datastore c02-ct1. This cluster hosts VMs tinyvm01 to tinyvm10.
- C06 hosts make up the c06 compute cluster. It uses the container/datastore c06-ct1. This cluster hosts VMs tinyvm11 to tinyvm20.
- We will protect the VMs running in c06 (tinyvm11 to tinyvm20) using an Async DR protection domain which will replicate every hour.
Figure 4 gives you an overview of that setup:
Step 1: Configure the remote sites at each end
- On c02, in Prism, go to the “Protection Domain” view and select “+ Remote Site > Physical Cluster”:
- Name the remote site (in this example, we’ll call it c06) and give it the Nutanix cluster virtual IP address (if you haven’t configured one yet, you can do that by simply clicking the Nutanix cluster name in the upper left corner in Prism):
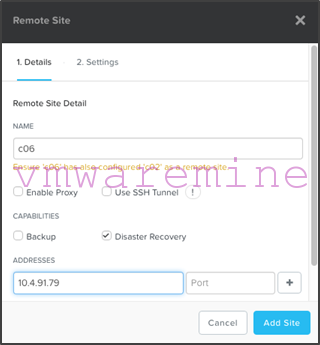
- Click on “Add Site”. Note that you can choose to modify options for the remote site such as bandwidth throttling if you want to, but you don’t have to.
- Now on c06, create the c02 remote site in the same fashion, except this time after clicking “Add Site”, we will configure a vstore (aka container) mapping from c06-ct1 to c02-ct1 (so that the system knows in which container it will replicate snapshots for VMs that are in the c06-ct1 container):
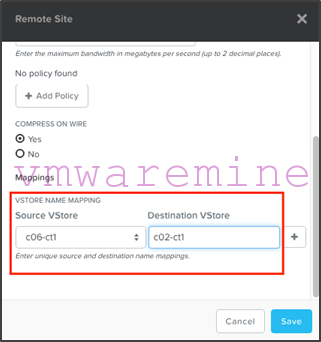
Make sure you create the opposite vstore mapping on the c06 remote site definition for c02 (this will be important when you’ll want to fail back).
Step 2: Create the Async DR protection domain with an hourly schedule
Now that we’ve got the remote sites sorted out, let’s create the protection domain.
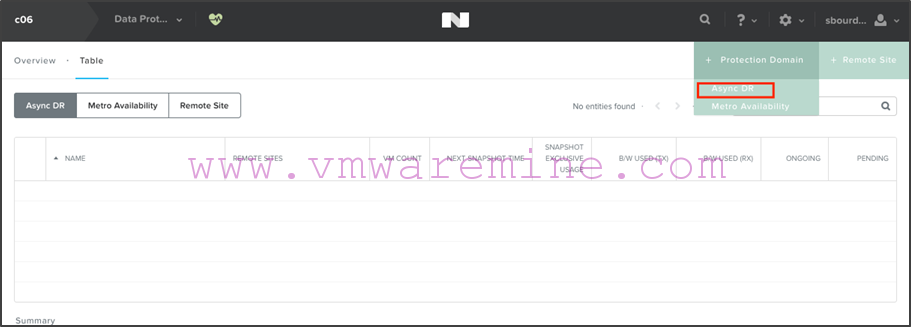
- On c06, in the “Protection Domain” view, click on “+ Protection Domain > Async DR”:
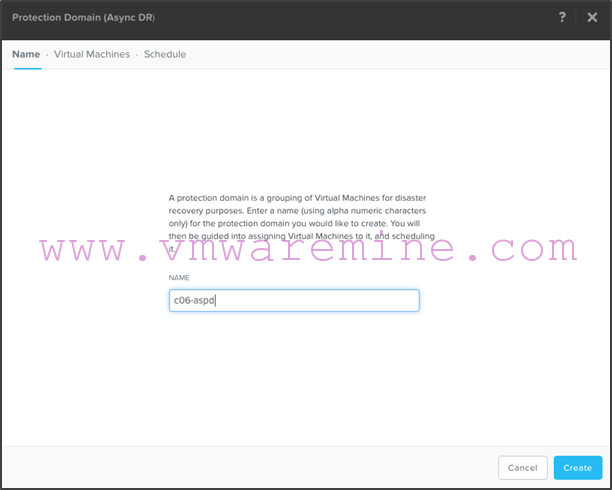
- We’ll call our protection domain “c06-aspd” (for c06 async protection domain):
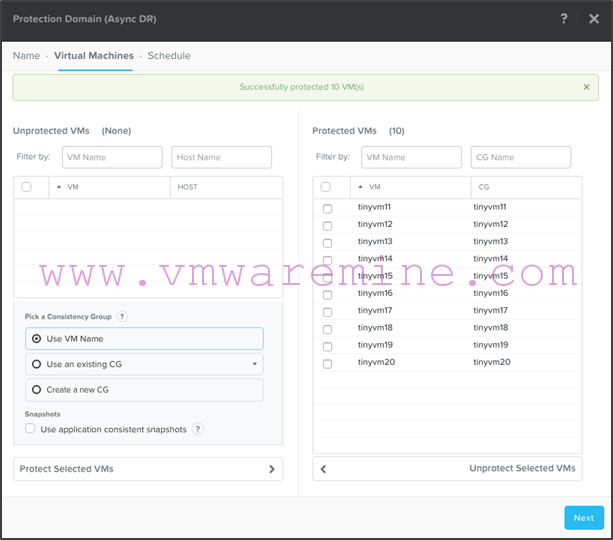
- Select the VMs you want to protect and click “Protect selected VMs”. Note that this is on a per-vm basis, not a per-container basis. You can also choose to regroup specific VMs in consistency group and enable application consistent snapshots if you are running vSphere and you have VMware Tools installed. When you’re done, click “Next”:
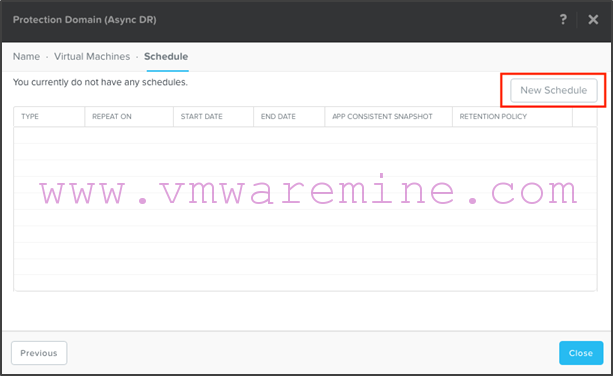
- Click on “New Schedule”:
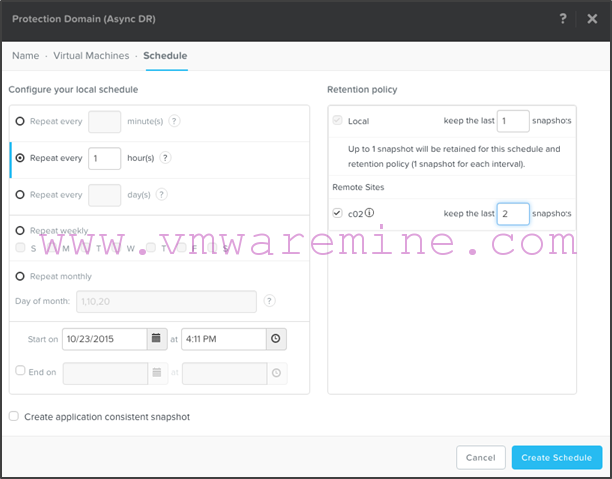
- Select the schedule you want (here we selected every 1 hour). Then select a local retention policy (we left the default of 1) and select the remote site for replication as well as a remote site retention (we changed it to 2 in this example). When done, click on “Create Schedule”:
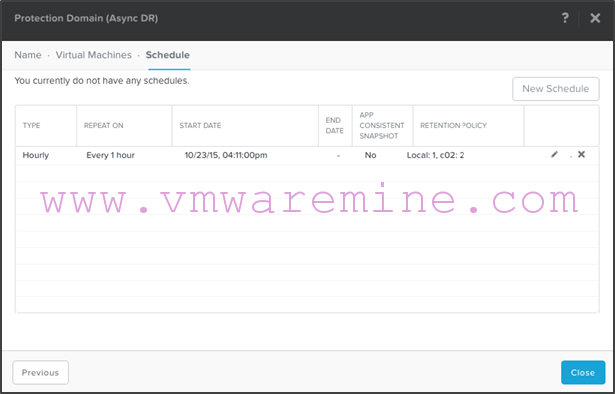
- Review your schedule and click on “Close”:
- When you select your protection domain, you’ll see that you can view which VMs are included, which snapshots are local or remote, all in the bottom part of the screen:
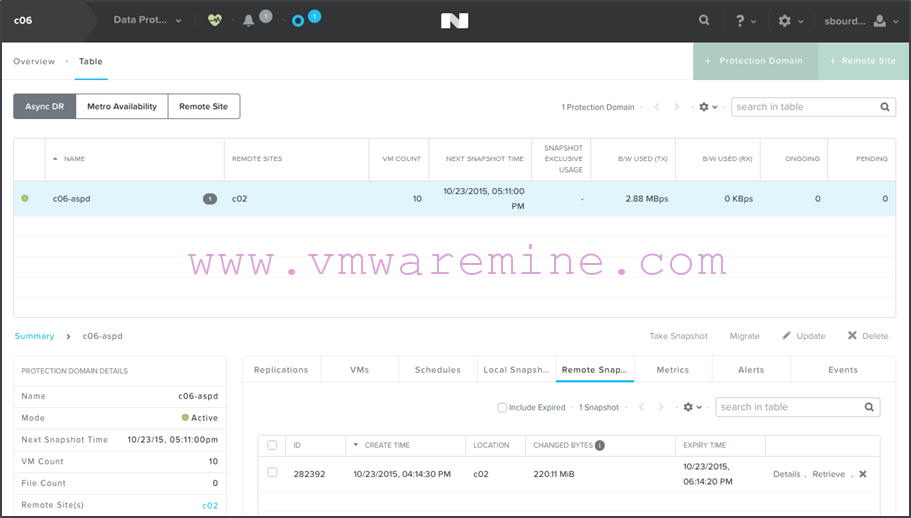
- On c02, you’ll see the Async DR PD as well, except the little circle on the left will be grey instead of green to show it is not active:
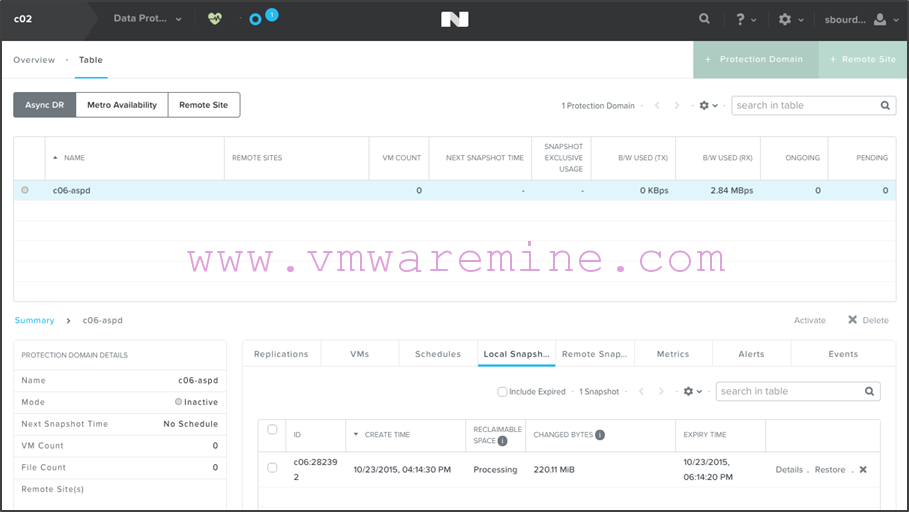
That’s it, you’ve configured your Async DR! Give yourself a pat on the back.
Configuring Metro Availability
Configuring Metro Availability is easy. At a high level, the workflow is as follows (assuming you already have your single vSphere cluster configured and ready):
- You create a new container on the target site which has the exact same name as the container at the source
- You define the target remote site on the source cluster in the Data Protection screen, then you define the source remote site on the target cluster also in the Data Protection screen
- On the source cluster, you add a Protection Domain of type Metro Availability, define the source container, select the remote site and select the VM Availability policy (more on that in a second)
- That’s it! Well, not quite… Remember that you still need to define DRS affinity rules to make sure that VMs run on hosts which have the active copy of the container in order to avoid cross site I/Os… That means you need to figure out which hosts are in each Nutanix cluster, which VMs are in which datastores, which datastore is active on which Nutanix cluster, then make sure VMs are on hosts which have the active container that maps to their datastore. Sounds complex but it really isn’t and I have even included a Powershell script to automate that for you. It’s available below when I go thru a specific example of configuring MA in my lab.
So what the hell is a VM Availability policy you ask? Good question.
A Metro Availability Protection Domain can have one of two roles and several different statuses. The roles are “Active” or “Standby”. As you have probably guessed, under normal circumstances, the role is Active on the source cluster and Standby on the target cluster.
The statuses are “Pending”, “Enabled in Sync”, “Remote Unreachable”, “Disabled” and “Decoupled”. “Pending” means a replication is occurring and success or failure has not been determined yet. “Enabled in Sync” means replication is on-going without any issue. This is the normal status under normal conditions. “Remote Unreachable” means that the remote site cannot be contacted. When this happens on a Standby PD, it just means data isn’t replicated anymore. On the Active PD however, I/Os will be suspended until the status is changed to “Disabled” or connectivity to the remote site is restored. “Disabled” means that the Protection Domain is no longer replicating, either because the remote site is unavailable, or because an administrator manually disabled the protection domain. “Decoupled” means that the protection domain is active both at the source and target and therefore out of sync. This is what happens after an unplanned site failure and can be easily remedied, but more on that in part 3 of this blog series.
Back to VM Availability policy: when a Metro Availability Protection Domain is in the “Remote Unreachable” status, all VM write I/Os are suspended in order to maintain consistency and avoid the “Decoupled” status. To resume VM write I/Os (which is what you would want if a disaster had occurred at the site to which you were replicating), the protection domain has to be in the “Disabled” status (meaning replication is stopped). That can be either a manual action (an admin logs in and disables the protection domain), or automatic (the Nutanix cluster will automatically set the status to disabled after a given number of seconds). Which option you choose is what defines the VM Availability policy. Note that this is NOT for standby protection domains, but active protection domains which have lost their replication partners. Think of it this way: replication is down, so any new data written will not be protected anymore, therefore someone needs to decide what to do: either this is legitimate because there was a site failure and therefore we can resume I/Os by changing the status to disabled, or we are in a split brain situation, in which case it may be better to power off VMs. Changing your VM Availability policy lets you choose whether you want that decision to be automatic or manual.
The table below summarizes the statuses for a Metro Availability Protection Domain:
|
Status |
What does it mean? |
What should I do? |
|
Pending |
A replication is occurring and status has not yet been determined |
Nothing other than wait to see what the next status will be (“Enabled in Sync” or “Remote Unreachable”) |
|
Enabled in Sync |
Replication is working |
Nothing, everything is peachy |
|
Remote Unreachable |
A replication failed |
If this is your active PD and your VM availability policy is manual, then you will need to decide if you prefer to power off your VMs or change the PD status to “Disabled” (which is what you want if you know for sure the remote site has crashed) |
|
Disabled |
Replication has been disabled |
Determine which site should be Active and re-enable replication from that site on the PD after you’ve determined that everything is back to normal |
|
Decoupled |
PD is active on both sites |
Shut down your VMs, determine which site has the most recent copy (should be the secondary site since the decoupled status is what happens after the primary site has recovered from failure), then change the status to “Disabled” on the other site, and re-enable on the site with the valid copy of the data. |
So if you’re like me, after reading this you’re thinking “Muh, sounds easy enough, but I’d like to see what it really looks like”. Fear not, for I have included below monkey-proof screenshots.
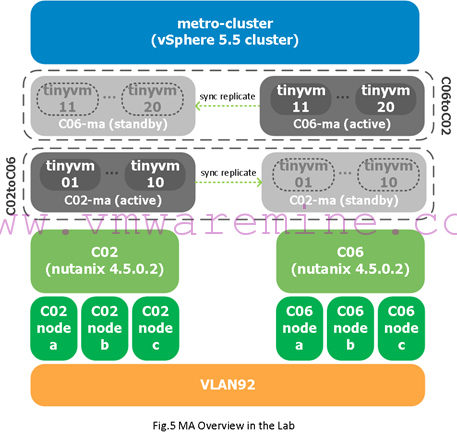
My setup is as follows:
- I have two Nutanix clusters: c02 and c06. Each Nutanix cluster has three nodes (c02nodea, c02nodeb and c02nodec for c02, and c06nodea, c06nodeb and c06nodec for c06).
- All hosts are running vSphere 5.5 and pooled into a single compute cluster which I called “metro-cluster”
- Nutanix cluster c02 will have an active protection domain of type MA called C02toC06 and which will apply to container c02-ma. This container will host VMs tinyvm01 to tinyvm10.
- Nutanix cluster c06 will have an active protection domain of type MA called C06toC02 and which will apply to container c06-ma. This container will host VMs tinyvm11 to tinyvm20.
- DRS affinity rules will be created to make sure tinyvm01 to tinyvm10 should run on hosts that make up c02 and that tinyvm11 to tinyvm20 should run on hosts that make up c06.
Figure 5 gives you an overview of that setup:
Now on with the actual configuration steps with screenshots:
Step 1: Create matching containers on each Nutanix cluster
First step is to make sure that the c02-ma container exists also on the c06 Nutanix cluster and that the c06-ma container exists also on the c02 Nutanix cluster. Remember, for MA to work, the replicated container must have a container on the target name with the same identical name.
- From c06’s Prism interface, we navigate to the Storage > Table > Containers view. Then click on the “+ Container” menu in the upper right corner:
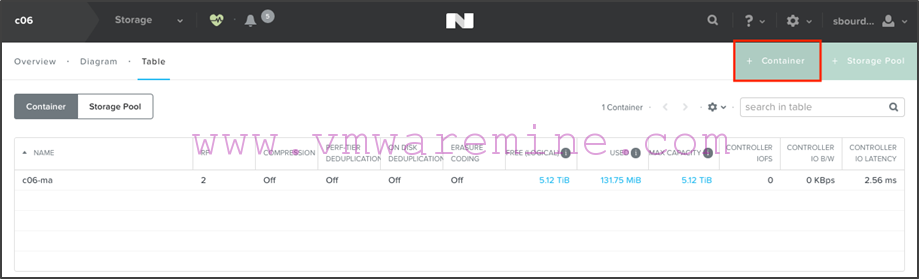
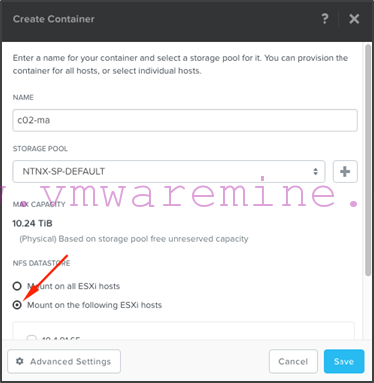
- Create the c02-ma container, and make sure you do not mount it on any of the hosts (otherwise your compute cluster may create data files on it in which case you won’t be able to select it as a replication target)
- Once the container has been created, you should see both containers listed on c06:
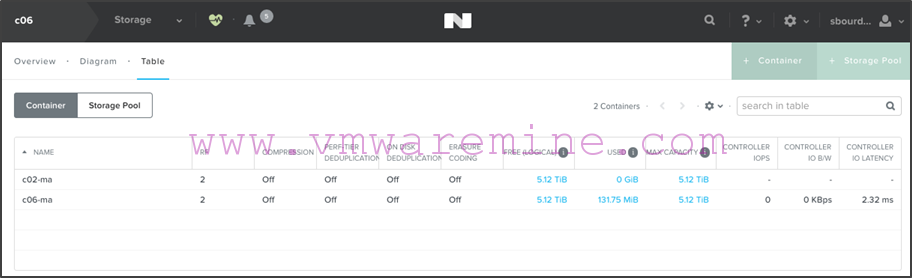
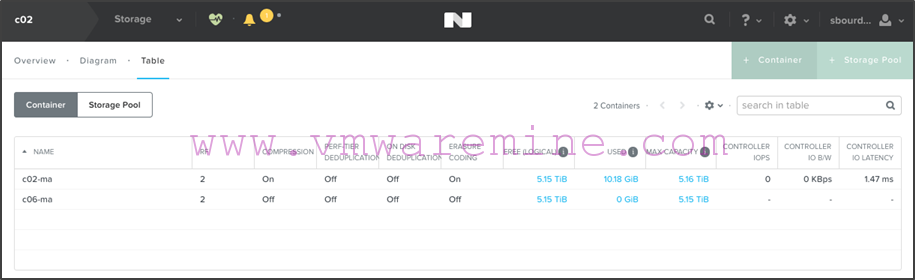
- Create c06-ma on c02 now by following the same procedure. Once done, this is what you will see on c02:
Step 2: Creating the remote sites on each Nutanix cluster
Now that we have set up our containers, we need to configure remote sites so that each Nutanix cluster becomes aware of the other. This is done in the “Protection Domain” view in Prism on each cluster. Note that we will use the Nutanix cluster virtual IP address (configured at installation time, or which can be configured in Prism by clicking the cluster name in the upper left corner).
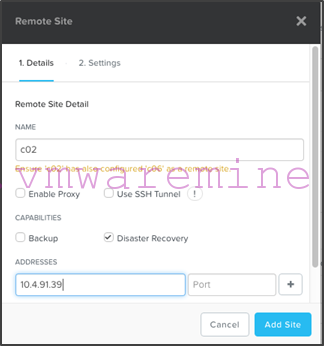
- On c06 Prism interface, add a “Remote Site” of type “Physical Cluster”:

- Give that site a meaningful name and put in the Nutanix cluster virtual IP address for c02:
- You can choose to configure specific settings (such as bandwidth throttling) on the next screen, but you don’t have to.
- Once added, you should see the remote site defined on c06:
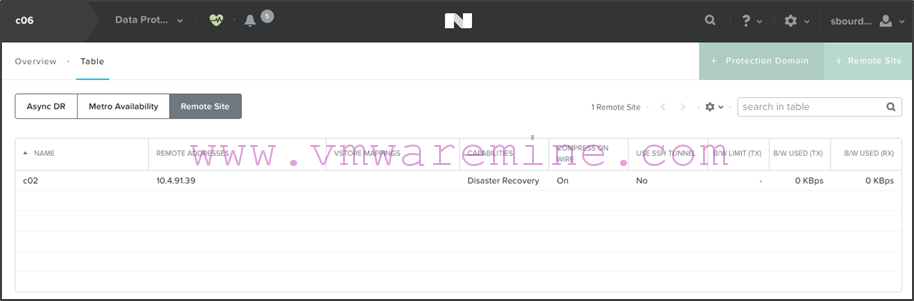
- Repeat the procedure on c02 in order to define the c06 remote site:
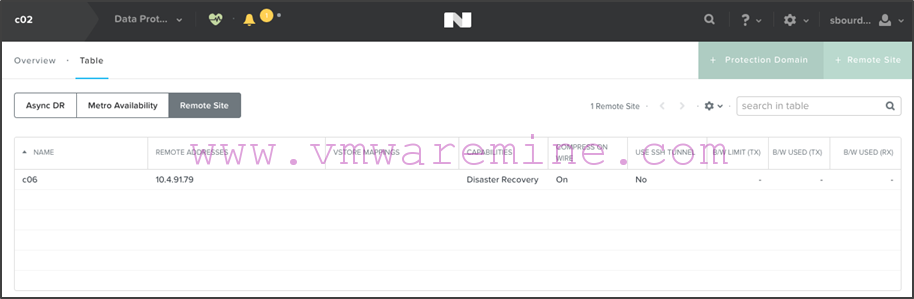
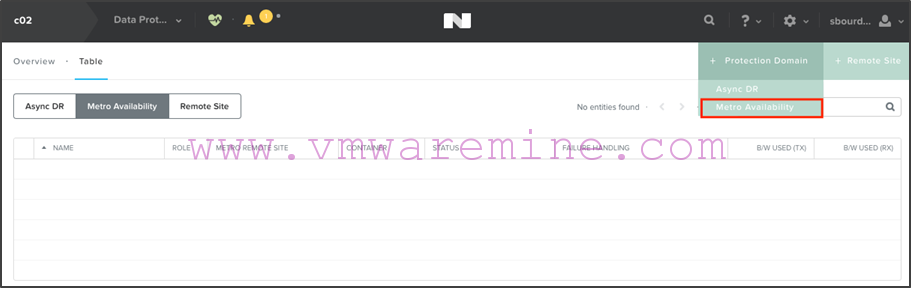
Step 3: Creating the Metro Availability Protection Domains
So now we have our containers set up as well as our remote sites. We are ready to create our Metro Availability Protection Domains. We will create one on c02 which will replicate the c02-ma container to c06, and one on c06 which will replicate the c06-ma container to c02.
- On c02, add a protection domain of type “Metro Availability”:
- We will call that protection domain “C02toC06”:
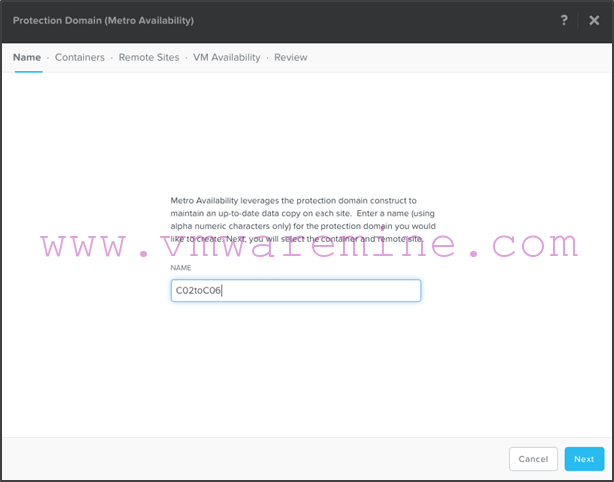
- Select c02-ma as the container you want to replicate:
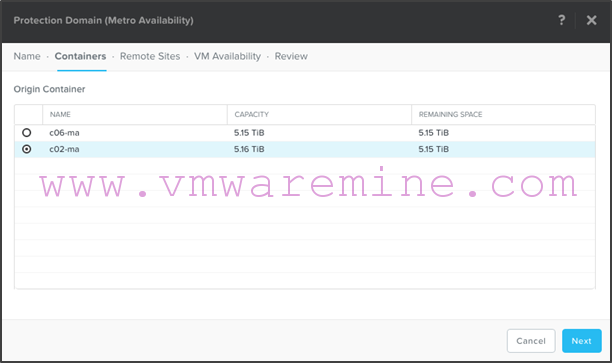
- Select c06 as the target site. Note that if network latency is too high, or if you have data in the target container, or if there is no existing target container defined, then the remote site will not be selectable as a target. Hover your mouse over whatever is causing the issue and resolve it in order to be able to select the remote site as a target:
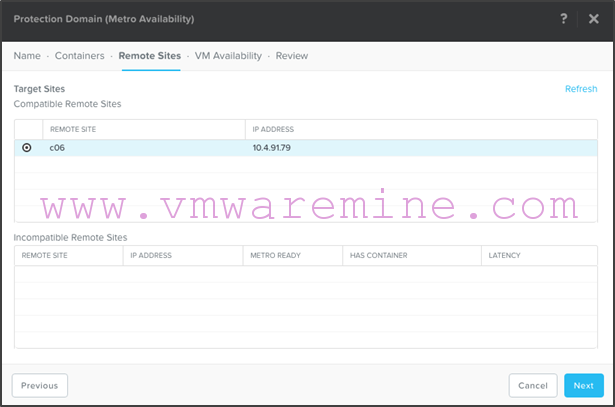
- Configure a VM Availability policy (manual or automatic). In this example, we will select automatic after 20 seconds. Remember, this is what will happen if the replication partner is lost. By choosing automatic, we are telling the Nutanix cluster to stop replication by changing the status of the protection domain to disabled so that VM write i/o can resume on the container.
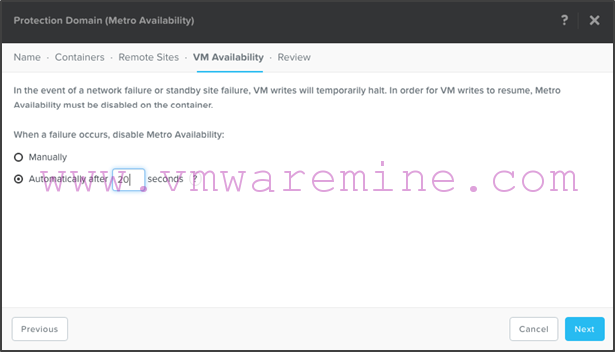
- Review the configuration before clicking “Create”:
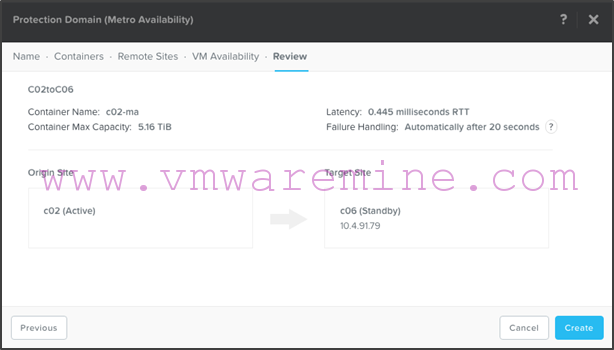
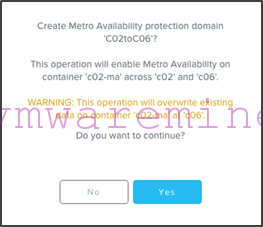
- Note that the system will warn you that you are about to overwrite anything that is on the c02-ma container at the target site (c06). This is because replication will start immediately:
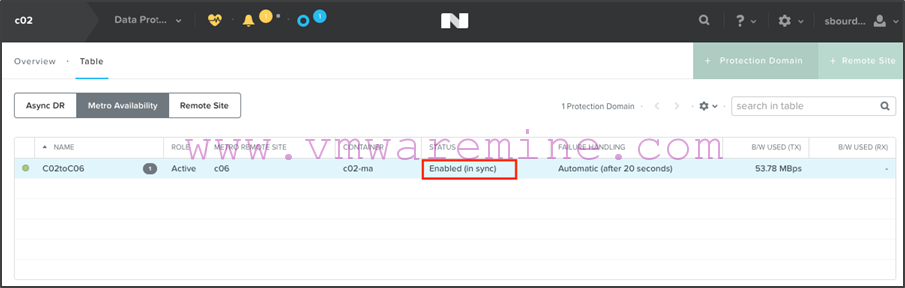
- After initial replication is performed, you will see that the protection domain is in the “Enabled in sync” status, which is what you want:
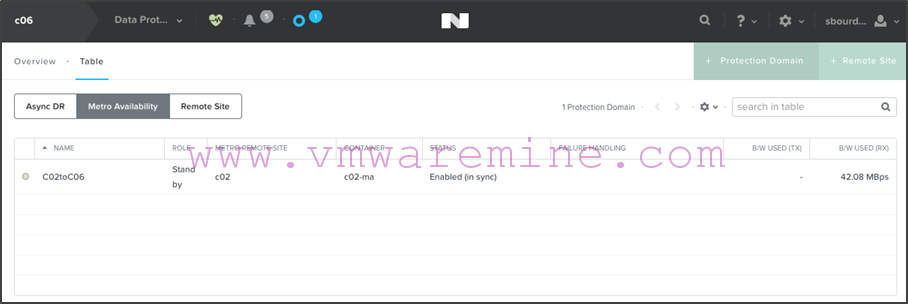
Note that if we look at what it looks like from c06, we’ll see pretty much the same view, except the protection domain will be marked as “Standby” instead of “Active”:
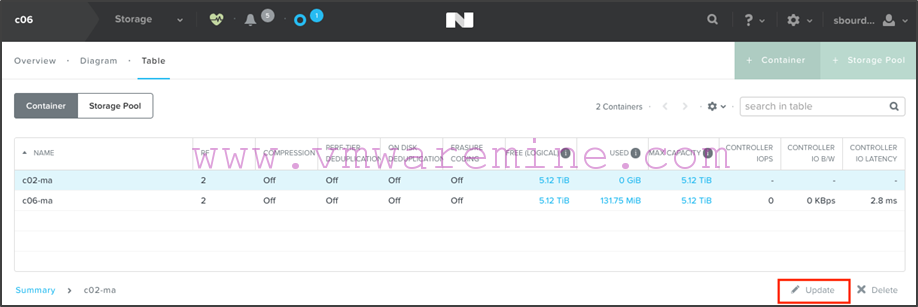
- We are now ready to mount the c02-ma container on c06. From c06 Prism interface, go to the “Storage > Table > Container” view and update the c02-ma container:
- Select the “Mount on all ESXi hosts” option and click “Save”:
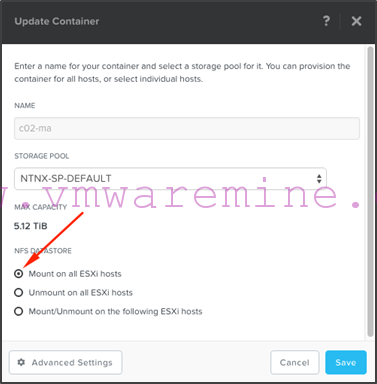
- Repeat the procedure on c06 to create a metro availability protection domain for the c06-ma container which will replicate to c02 as the target site. When done, you should see the following from c06 protection domain, metro availability view:
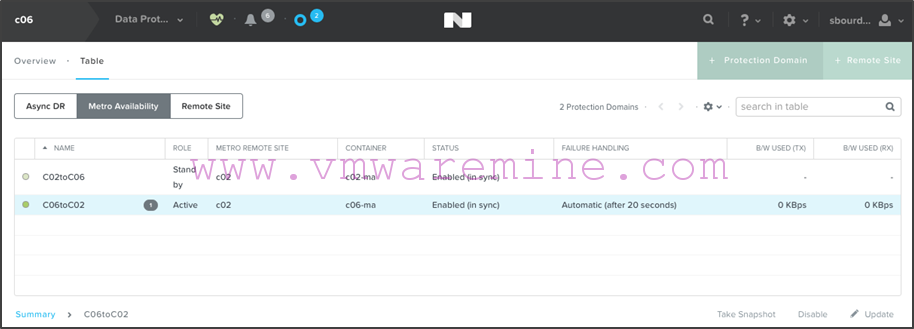
Note that C06toC02 is active on c06 while C02toC06 is standby. Both as “Enabled in sync”. If we look on c02, we’ll see that the active and standby protection domains are reversed:
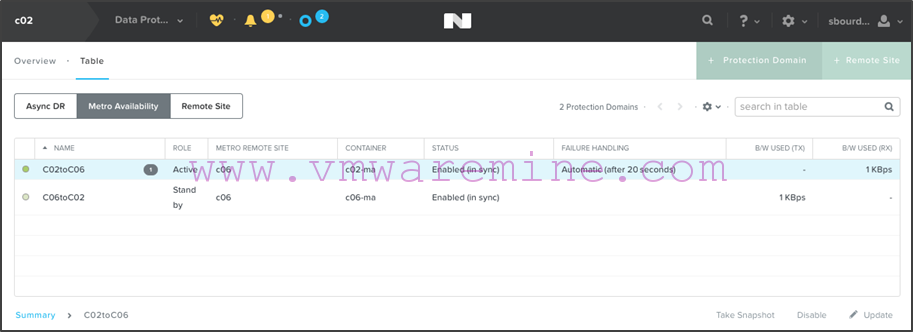
Step 4: Creating the vSphere DRS affinity rules with a Powershell script
So now our protection domains have been created, what’s next? Well, if you remember what was said earlier in this post, we still need to create DRS affinity rules on the compute cluster so that VMs which have their storage on the c02 Nutanix cluster don’t run on hosts which are in the c06 Nutanix cluster (which only has a standby copy of the container/datastore) and vice versa.
That means we need to understand:
- Which compute hosts belong to which Nutanix cluster
- Which datastores are replicated as part of a Metro Availability protection domain
- Which VMs are in those datastores
Then we will need to:
- Create DRS host and VM groups
- Create “should” VM to host affinity rules
That can be a somewhat tedious task, but thankfully, I have written a script for you that will automate all that.
Before we get into the script, let’s review what our environment looks like from the vSphere client.
- We have a single compute cluster regrouping all the Nutanix nodes and with HA and DRS enabled:
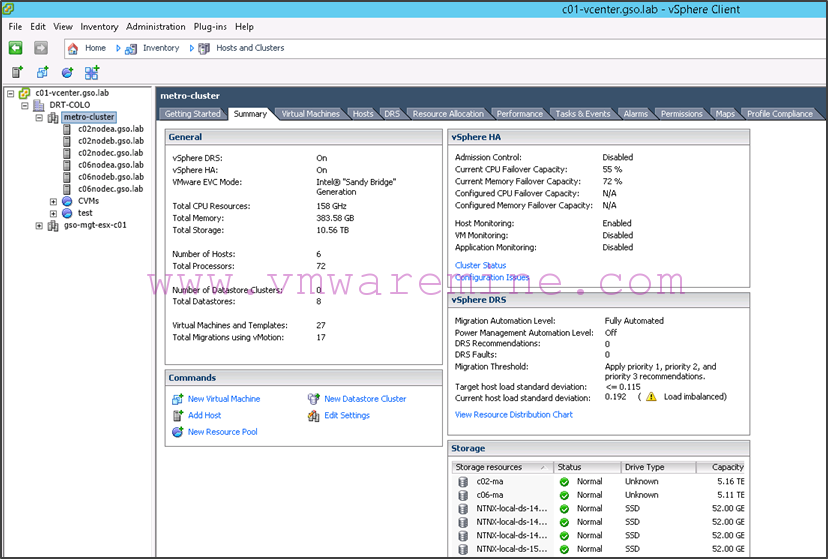
- Any host in that compute cluster can see both replicated datastores:
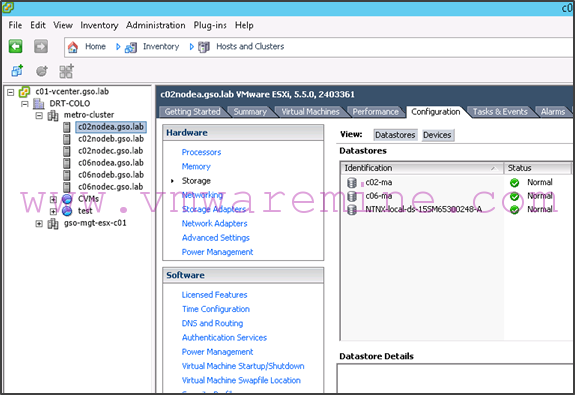
- Some VMs are running in the c02-ma datastore while others are running in the c06-ma datastore:
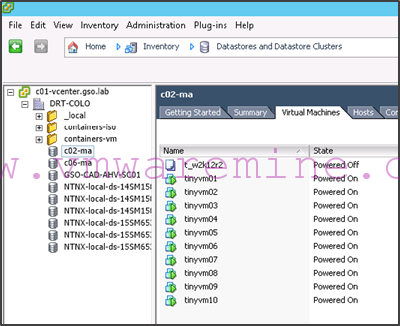
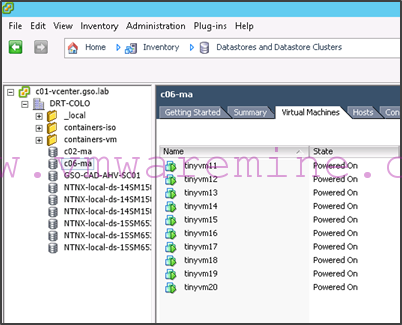
Given this configuration, we want tinyvm01 to tinyvm10 to run on c02 hosts and tinyvm11 to tinyvm20 to run on c06 hosts. This will make sure that there is no cross-site i/o traffic and that the cross-site network bandwidth will be used exclusively for replication.
For that purpose, we can use the add-DRSAffinityRulesForMA.ps1 script which you can download below. The script will prompt you for what it needs (the Nutanix clusters IP addresses and credentials, as well as the vCenter server IP address) and will create the DRS host and vm groups and vm to host rules:
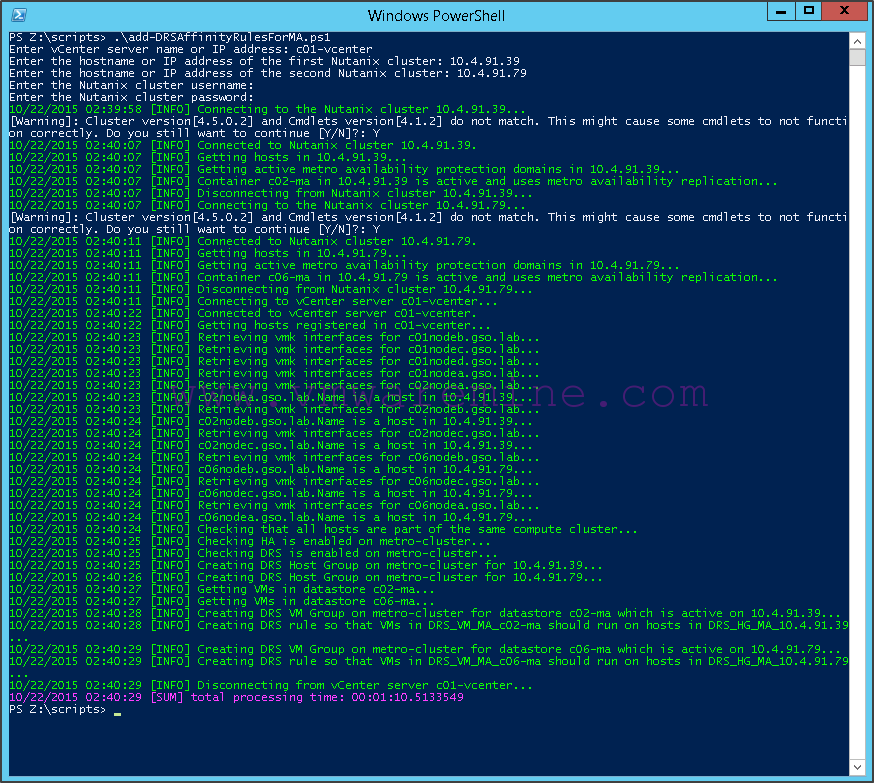
Note that to correlate Nutanix hosts to vSphere compute hosts, it uses the management IP address (vmk0) as a key. If you don’t like the DRS groups or rules names, you can always change them later.
Once done, the script has created the following groups:
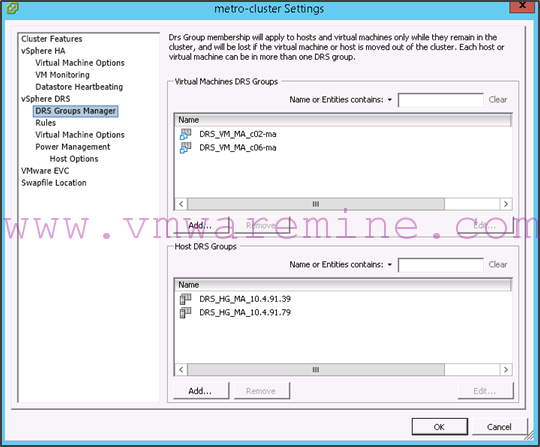
In addition, the following rules have been created:
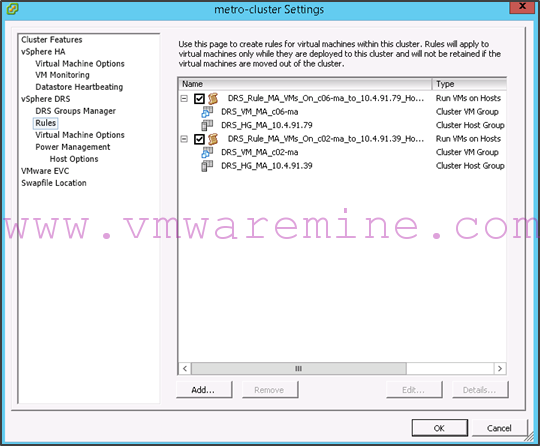
Here is the script for you to download: add-DRSAffinityRulesForMA.ps1
Note that it requires PowerCLI and the Nutanix cmdlets to be installed. For instructions on how to set that up, refer to this blog post.
I have also included below the source code (JULY 2016 EDIT: I updated the script to be able to deal with updating the rules. Note that the object naming convention changed to make the objects more readable as well):
<#
.SYNOPSIS
This script is used to create DRS affinity groups and rules based on the Nutanix Metro Availability setup of a vSphere cluster.
.DESCRIPTION
The script will look at the Metro Availability setup for a pair of given Nutanix clusters and will create DRS affinity groups and rules so that VMs will run on hosts which hold the active copy of a given replicated datastore. This is to avoid I/O going over two sites in normal conditions. If DRS groups and rules already exist that match the naming convention used in this script, then it will update those groups and rules (unless you use the -noruleupdate switch in which case only groups will be updated). This script requires having both the Nutanix cmdlets and PowerCLI installed.
.PARAMETER help
Displays a help message (seriously, what did you think this was?)
.PARAMETER history
Displays a release history for this script (provided the editors were smart enough to document this...)
.PARAMETER log
Specifies that you want the output messages to be written in a log file as well as on the screen.
.PARAMETER debugme
Turns off SilentlyContinue on unexpected error messages.
.PARAMETER ntnx_cluster1
First Nutanix cluster fully qualified domain name or IP address.
.PARAMETER ntnx_cluster2
Second Nutanix cluster fully qualified domain name or IP address.
.PARAMETER username
Username used to connect to the Nutanix clusters.
.PARAMETER password
Password used to connect to the Nutanix clusters.
.PARAMETER vcenter
Hostname or IP address of the vCenter Server.
.PARAMETER noruleupdate
Use this switch if you do NOT want to update DRS rules. Only groups will be updated. This can be useful when using the script within the context of a failback.
.EXAMPLE
Create DRS affinity groups and rules for ntnxc1 and ntnxc2 on vcenter1:
PS> .\add-DRSAffinityRulesForMA.ps1 -ntnx_cluster1 ntnxc1.local -ntnx_cluster2 ntnxc2.local -username admin -password nutanix/4u -vcenter vcenter1.local
.LINK
http://www.nutanix.com/services
.NOTES
Author: Stephane Bourdeaud (sbourdeaud@nutanix.com)
Revision: June 22nd 2016
#>
######################################
## parameters and initial setup ##
######################################
#let's start with some command line parsing
Param
(
#[parameter(valuefrompipeline = $true, mandatory = $true)] [PSObject]$myParam1,
[parameter(mandatory = $false)] [switch]$help,
[parameter(mandatory = $false)] [switch]$history,
[parameter(mandatory = $false)] [switch]$log,
[parameter(mandatory = $false)] [switch]$debugme,
[parameter(mandatory = $false)] [string]$ntnx_cluster1,
[parameter(mandatory = $false)] [string]$ntnx_cluster2,
[parameter(mandatory = $false)] [string]$username,
[parameter(mandatory = $false)] [string]$password,
[parameter(mandatory = $false)] [string]$vcenter,
[parameter(mandatory = $false)] [switch]$noruleupdate
)
# get rid of annoying error messages
if (!$debugme) {$ErrorActionPreference = "SilentlyContinue"}
########################
## main functions ##
########################
#this function is used to output log data
Function OutputLogData
{
#input: log category, log message
#output: text to standard output
<#
.SYNOPSIS
Outputs messages to the screen and/or log file.
.DESCRIPTION
This function is used to produce screen and log output which is categorized, time stamped and color coded.
.NOTES
Author: Stephane Bourdeaud
.PARAMETER myCategory
This the category of message being outputed. If you want color coding, use either "INFO", "WARNING", "ERROR" or "SUM".
.PARAMETER myMessage
This is the actual message you want to display.
.EXAMPLE
PS> OutputLogData -mycategory "ERROR" -mymessage "You must specify a cluster name!"
#>
param
(
[string] $category,
[string] $message
)
begin
{
$myvarDate = get-date
$myvarFgColor = "Gray"
switch ($category)
{
"INFO" {$myvarFgColor = "Green"}
"WARNING" {$myvarFgColor = "Yellow"}
"ERROR" {$myvarFgColor = "Red"}
"SUM" {$myvarFgColor = "Magenta"}
}
}
process
{
Write-Host -ForegroundColor $myvarFgColor "$myvarDate [$category] $message"
if ($log) {Write-Output "$myvarDate [$category] $message" >>$myvarOutputLogFile}
}
end
{
Remove-variable category
Remove-variable message
Remove-variable myvarDate
Remove-variable myvarFgColor
}
}#end function OutputLogData
#this function is used to create a DRS host group
Function New-DrsHostGroup
{
<#
.SYNOPSIS
Creates a new DRS host group
.DESCRIPTION
This function creates a new DRS host group in the DRS Group Manager
.NOTES
Author: Arnim van Lieshout
.PARAMETER VMHost
The hosts to add to the group. Supports objects from the pipeline.
.PARAMETER Cluster
The cluster to create the new group on.
.PARAMETER Name
The name for the new group.
.EXAMPLE
PS> Get-VMHost ESX001,ESX002 | New-DrsHostGroup -Name "HostGroup01" -Cluster CL01
.EXAMPLE
PS> New-DrsHostGroup -Host ESX001,ESX002 -Name "HostGroup01" -Cluster (Get-CLuster CL01)
#>
Param(
[parameter(valuefrompipeline = $true, mandatory = $true,
HelpMessage = "Enter a host entity")]
[PSObject]$VMHost,
[parameter(mandatory = $true,
HelpMessage = "Enter a cluster entity")]
[PSObject]$Cluster,
[parameter(mandatory = $true,
HelpMessage = "Enter a name for the group")]
[String]$Name)
begin {
switch ($Cluster.gettype().name) {
"String" {$cluster = Get-Cluster $cluster | Get-View}
"ClusterImpl" {$cluster = $cluster | Get-View}
"Cluster" {}
default {throw "No valid type for parameter -Cluster specified"}
}
$spec = New-Object VMware.Vim.ClusterConfigSpecEx
$group = New-Object VMware.Vim.ClusterGroupSpec
$group.operation = "add"
$group.Info = New-Object VMware.Vim.ClusterHostGroup
$group.Info.Name = $Name
}
Process {
switch ($VMHost.gettype().name) {
"String[]" {Get-VMHost -Name $VMHost | %{$group.Info.Host += $_.Extensiondata.MoRef}}
"String" {Get-VMHost -Name $VMHost | %{$group.Info.Host += $_.Extensiondata.MoRef}}
"VMHostImpl" {$group.Info.Host += $VMHost.Extensiondata.MoRef}
"HostSystem" {$group.Info.Host += $VMHost.MoRef}
default {throw "No valid type for parameter -VMHost specified"}
}
}
End {
if ($group.Info.Host) {
$spec.GroupSpec += $group
$cluster.ReconfigureComputeResource_Task($spec,$true) | Out-Null
}
else {
throw "No valid hosts specified"
}
}
}
#this function is used to create a DRS VM group
Function New-DrsVmGroup
{
<#
.SYNOPSIS
Creates a new DRS VM group
.DESCRIPTION
This function creates a new DRS VM group in the DRS Group Manager
.NOTES
Author: Arnim van Lieshout
.PARAMETER VM
The VMs to add to the group. Supports objects from the pipeline.
.PARAMETER Cluster
The cluster to create the new group on.
.PARAMETER Name
The name for the new group.
.EXAMPLE
PS> Get-VM VM001,VM002 | New-DrsVmGroup -Name "VmGroup01" -Cluster CL01
.EXAMPLE
PS> New-DrsVmGroup -VM VM001,VM002 -Name "VmGroup01" -Cluster (Get-CLuster CL01)
#>
Param(
[parameter(valuefrompipeline = $true, mandatory = $true,
HelpMessage = "Enter a vm entity")]
[PSObject]$VM,
[parameter(mandatory = $true,
HelpMessage = "Enter a cluster entity")]
[PSObject]$Cluster,
[parameter(mandatory = $true,
HelpMessage = "Enter a name for the group")]
[String]$Name)
begin {
switch ($Cluster.gettype().name) {
"String" {$cluster = Get-Cluster $cluster | Get-View}
"ClusterImpl" {$cluster = $cluster | Get-View}
"Cluster" {}
default {throw "No valid type for parameter -Cluster specified"}
}
$spec = New-Object VMware.Vim.ClusterConfigSpecEx
$group = New-Object VMware.Vim.ClusterGroupSpec
$group.operation = "add"
$group.Info = New-Object VMware.Vim.ClusterVmGroup
$group.Info.Name = $Name
}
Process {
switch ($VM.gettype().name) {
"String[]" {Get-VM -Name $VM | %{$group.Info.VM += $_.Extensiondata.MoRef}}
"String" {Get-VM -Name $VM | %{$group.Info.VM += $_.Extensiondata.MoRef}}
"VirtualMachineImpl" {$group.Info.VM += $VM.Extensiondata.MoRef}
"VirtualMachine" {$group.Info.VM += $VM.MoRef}
default {throw "No valid type for parameter -VM specified"}
}
}
End {
if ($group.Info.VM) {
$spec.GroupSpec += $group
$cluster.ReconfigureComputeResource_Task($spec,$true) | Out-Null
}
else {
throw "No valid VMs specified"
}
}
}
#this function is used to create a VM to host DRS rule
Function New-DRSVMToHostRule
{
<#
.SYNOPSIS
Creates a new DRS VM to host rule
.DESCRIPTION
This function creates a new DRS vm to host rule
.NOTES
Author: Arnim van Lieshout
.PARAMETER VMGroup
The VMGroup name to include in the rule.
.PARAMETER HostGroup
The VMHostGroup name to include in the rule.
.PARAMETER Cluster
The cluster to create the new rule on.
.PARAMETER Name
The name for the new rule.
.PARAMETER AntiAffine
Switch to make the rule an AntiAffine rule. Default rule type is Affine.
.PARAMETER Mandatory
Switch to make the rule mandatory (Must run rule). Default rule is not mandatory (Should run rule)
.EXAMPLE
PS> New-DrsVMToHostRule -VMGroup "VMGroup01" -HostGroup "HostGroup01" -Name "VMToHostRule01" -Cluster CL01 -AntiAffine -Mandatory
#>
Param(
[parameter(mandatory = $true,
HelpMessage = "Enter a VM DRS group name")]
[String]$VMGroup,
[parameter(mandatory = $true,
HelpMessage = "Enter a host DRS group name")]
[String]$HostGroup,
[parameter(mandatory = $true,
HelpMessage = "Enter a cluster entity")]
[PSObject]$Cluster,
[parameter(mandatory = $true,
HelpMessage = "Enter a name for the group")]
[String]$Name,
[Switch]$AntiAffine,
[Switch]$Mandatory)
switch ($Cluster.gettype().name) {
"String" {$cluster = Get-Cluster $cluster | Get-View}
"ClusterImpl" {$cluster = $cluster | Get-View}
"Cluster" {}
default {throw "No valid type for parameter -Cluster specified"}
}
$spec = New-Object VMware.Vim.ClusterConfigSpecEx
$rule = New-Object VMware.Vim.ClusterRuleSpec
$rule.operation = "add"
$rule.info = New-Object VMware.Vim.ClusterVmHostRuleInfo
$rule.info.enabled = $true
$rule.info.name = $Name
$rule.info.mandatory = $Mandatory
$rule.info.vmGroupName = $VMGroup
if ($AntiAffine) {
$rule.info.antiAffineHostGroupName = $HostGroup
}
else {
$rule.info.affineHostGroupName = $HostGroup
}
$spec.RulesSpec += $rule
$cluster.ReconfigureComputeResource_Task($spec,$true) | Out-Null
}
#this function is used to edit an existing DRS rule
Function Update-DrsVMGroup
{
<#
.SYNOPSIS
Update DRS VM group with a new collection of VM´s
.DESCRIPTION
Use this function to update the ClusterVMgroup with VMs that are sent in by parameters
.PARAMETER xyz
.NOTES
Author: Niklas Akerlund / RTS (most of the code came from http://communities.vmware.com/message/1667279 @LucD22 and GotMoo)
Date: 2012-06-28
#>
param
(
$cluster,
$VMs,
$groupVMName
)
$cluster = Get-Cluster $cluster
$spec = New-Object VMware.Vim.ClusterConfigSpecEx
$groupVM = New-Object VMware.Vim.ClusterGroupSpec
#Operation edit will replace the contents of the GroupVMName with the new contents seleced below.
$groupVM.operation = "edit"
$groupVM.Info = New-Object VMware.Vim.ClusterVmGroup
$groupVM.Info.Name = $groupVMName
Get-VM $VMs | %{$groupVM.Info.VM += $_.Extensiondata.MoRef}
$spec.GroupSpec += $groupVM
#Apply the settings to the cluster
$cluster.ExtensionData.ReconfigureComputeResource($spec,$true)
}
#this function is used to edit an existing DRS rule
Function Update-DrsHostGroup
{
<#
.SYNOPSIS
Update DRS Host group with a new collection of Hosts
.DESCRIPTION
Use this function to update the ClusterHostgroup with Hosts that are sent in by parameters
.PARAMETER xyz
.NOTES
Author: Niklas Akerlund / RTS (most of the code came from http://communities.vmware.com/message/1667279 @LucD22 and GotMoo)
Date: 2012-06-28
#>
param
(
$cluster,
$Hosts,
$groupHostName
)
$cluster = Get-Cluster $cluster
$spec = New-Object VMware.Vim.ClusterConfigSpecEx
$groupHost = New-Object VMware.Vim.ClusterGroupSpec
#Operation edit will replace the contents of the GroupVMName with the new contents seleced below.
$groupHost.operation = "edit"
$groupHost.Info = New-Object VMware.Vim.ClusterHostGroup
$groupHost.Info.Name = $groupHostName
Get-VMHost $Hosts | %{$groupHost.Info.Host += $_.Extensiondata.MoRef}
$spec.GroupSpec += $groupHost
#Apply the settings to the cluster
$cluster.ExtensionData.ReconfigureComputeResource($spec,$true)
}
#this function is used to create a VM to host DRS rule
Function Update-DRSVMToHostRule
{
<#
.SYNOPSIS
Creates a new DRS VM to host rule
.DESCRIPTION
This function creates a new DRS vm to host rule
.NOTES
Author: Arnim van Lieshout
.PARAMETER VMGroup
The VMGroup name to include in the rule.
.PARAMETER HostGroup
The VMHostGroup name to include in the rule.
.PARAMETER Cluster
The cluster to create the new rule on.
.PARAMETER Name
The name for the new rule.
.PARAMETER AntiAffine
Switch to make the rule an AntiAffine rule. Default rule type is Affine.
.PARAMETER Mandatory
Switch to make the rule mandatory (Must run rule). Default rule is not mandatory (Should run rule)
.EXAMPLE
PS> New-DrsVMToHostRule -VMGroup "VMGroup01" -HostGroup "HostGroup01" -Name "VMToHostRule01" -Cluster CL01 -AntiAffine -Mandatory
#>
Param(
[parameter(mandatory = $true,
HelpMessage = "Enter a VM DRS group name")]
[String]$VMGroup,
[parameter(mandatory = $true,
HelpMessage = "Enter a DRS rule key")]
[String]$RuleKey,
[parameter(mandatory = $true,
HelpMessage = "Enter a DRS rule uuid")]
[String]$RuleUuid,
[parameter(mandatory = $true,
HelpMessage = "Enter a host DRS group name")]
[String]$HostGroup,
[parameter(mandatory = $true,
HelpMessage = "Enter a cluster entity")]
[PSObject]$Cluster,
[parameter(mandatory = $true,
HelpMessage = "Enter a name for the group")]
[String]$Name,
[Switch]$AntiAffine,
[Switch]$Mandatory)
switch ($Cluster.gettype().name) {
"String" {$cluster = Get-Cluster $cluster | Get-View}
"ClusterImpl" {$cluster = $cluster | Get-View}
"Cluster" {}
default {throw "No valid type for parameter -Cluster specified"}
}
$spec = New-Object VMware.Vim.ClusterConfigSpecEx
$rule = New-Object VMware.Vim.ClusterRuleSpec
$rule.operation = "edit"
$rule.info = New-Object VMware.Vim.ClusterVmHostRuleInfo
$rule.info.enabled = $true
$rule.info.name = $Name
$rule.info.mandatory = $Mandatory
$rule.info.vmGroupName = $VMGroup
$rule.info.Key = $RuleKey
$rule.info.RuleUuid = $RuleUuid
if ($AntiAffine) {
$rule.info.antiAffineHostGroupName = $HostGroup
}
else {
$rule.info.affineHostGroupName = $HostGroup
}
$spec.RulesSpec += $rule
$cluster.ReconfigureComputeResource_Task($spec,$true) | Out-Null
}
#########################
## main processing ##
#########################
#check if we need to display help and/or history
$HistoryText = @'
Maintenance Log
Date By Updates (newest updates at the top)
---------- ---- ---------------------------------------------------------------
10/06/2015 sb Initial release.
06/21/2016 sb Updated code to support refresh of existing rules as well as
partial groups and rules creation. Changed default groups and
rule naming to simplify them. Added the -noruleupdate switch.
################################################################################
'@
$myvarScriptName = ".\add-DRSAffinityRulesForMA.ps1"
if ($help) {get-help $myvarScriptName; exit}
if ($History) {$HistoryText; exit}
#let's make sure PowerCLI is being used
if ((Get-PSSnapin VMware.VimAutomation.Core -ErrorAction SilentlyContinue) -eq $null)#is it already there?
{
Add-PSSnapin VMware.VimAutomation.Core #no? let's add it
if (!$?) #have we been able to add it successfully?
{
OutputLogData -category "ERROR" -message "Unable to load the PowerCLI snapin. Please make sure PowerCLI is installed on this server."
return
}
}
#let's load the Nutanix cmdlets
if ((Get-PSSnapin -Name NutanixCmdletsPSSnapin -ErrorAction SilentlyContinue) -eq $null)#is it already there?
{
Add-PSSnapin NutanixCmdletsPSSnapin #no? let's add it
if (!$?) #have we been able to add it successfully?
{
OutputLogData -category "ERROR" -message "Unable to load the Nutanix snapin. Please make sure the Nutanix Cmdlets are installed on this server."
return
}
}
#initialize variables
#misc variables
$myvarElapsedTime = [System.Diagnostics.Stopwatch]::StartNew() #used to store script begin timestamp
$myvarvCenterServers = @() #used to store the list of all the vCenter servers we must connect to
$myvarOutputLogFile = (Get-Date -UFormat "%Y_%m_%d_%H_%M_")
$myvarOutputLogFile += "OutputLog.log"
############################################################################
# command line arguments initialization
############################################################################
#let's initialize parameters if they haven't been specified
if (!$vcenter) {$vcenter = read-host "Enter vCenter server name or IP address"}#prompt for vcenter server name
$myvarvCenterServers = $vcenter.Split(",") #make sure we parse the argument in case it contains several entries
if (!$ntnx_cluster1) {$ntnx_cluster1 = read-host "Enter the hostname or IP address of the first Nutanix cluster"}#prompt for the first Nutanix cluster name
if (!$ntnx_cluster2) {$ntnx_cluster2 = read-host "Enter the hostname or IP address of the second Nutanix cluster"}#prompt for the second Nutanix cluster name
if (!$username) {$username = read-host "Enter the Nutanix cluster username"}#prompt for the Nutanix cluster username
if (!$password) {$password = read-host "Enter the Nutanix cluster password"}#prompt for the Nutanix cluster password
$spassword = $password | ConvertTo-SecureString -AsPlainText -Force
################################
## Main execution here ##
################################
#building a variable containing the Nutanix cluster names
$myvarNutanixClusters = @($ntnx_cluster1,$ntnx_cluster2)
#initialize variables we'll need to store information about the Nutanix clusters
$myvarNtnxC1_hosts, $myvarNtnxC2_hosts, $myvarNtnxC1_MaActiveCtrs, $myvarNtnxC2_MaActiveCtrs = @()
$myvarCounter = 1
#connect to each Nutanix cluster to figure out the info we need
foreach ($myvarNutanixCluster in $myvarNutanixClusters)
{
OutputLogData -category "INFO" -message "Connecting to the Nutanix cluster $myvarNutanixCluster..."
if (!($myvarNutanixClusterConnect = Connect-NutanixCluster -Server $myvarNutanixCluster -UserName $username -Password $spassword –AcceptInvalidSSLCerts -ForcedConnection))#make sure we connect to the Nutanix cluster OK...
{#error handling
$myvarerror = $error[0].Exception.Message
OutputLogData -category "ERROR" -message "$myvarerror"
break #exit since we can't connect to one of the Nutanix clusters
}
else #...otherwise show confirmation
{
OutputLogData -category "INFO" -message "Connected to Nutanix cluster $myvarNutanixCluster."
}#endelse
if ($myvarNutanixClusterConnect)
{
###########################################
# processing for each Nutanix cluster here#
###########################################
if ($myvarCounter -eq 1)
{
#retrieve hostnames of nodes forming up this cluster
OutputLogData -category "INFO" -message "Getting hosts in $myvarNutanixCluster..."
$myvarNtnxC1_hosts = get-ntnxhost | Select -Property hypervisorAddress
#retrieve container names for active metro availability protection domains
OutputLogData -category "INFO" -message "Getting active metro availability protection domains in $myvarNutanixCluster..."
$myvarMaActivePDs = Get-NTNXProtectionDomain | where {($_.active -eq $true) -and ($_.metroAvail.role -eq "Active")} #figure out which protection domains are MA and active
$myvarNtnxC1_MaActiveCtrs = $myvarMaActivePDs | %{$_.metroAvail.container}
}
if ($myvarCounter -eq 2)
{
#retrieve hostnames of nodes forming up this cluster
OutputLogData -category "INFO" -message "Getting hosts in $myvarNutanixCluster..."
$myvarNtnxC2_hosts = get-ntnxhost | Select -Property hypervisorAddress
#retrieve container names for active metro availability protection domains
OutputLogData -category "INFO" -message "Getting active metro availability protection domains in $myvarNutanixCluster..."
$myvarMaActivePDs = Get-NTNXProtectionDomain | where {($_.active -eq $true) -and ($_.metroAvail.role -eq "Active")} #figure out which protection domains are MA and active
$myvarNtnxC2_MaActiveCtrs = $myvarMaActivePDs | %{$_.metroAvail.container}
}
}#endif
OutputLogData -category "INFO" -message "Disconnecting from Nutanix cluster $myvarNutanixCluster..."
Disconnect-NutanixCluster -Servers $myvarNutanixCluster #cleanup after ourselves and disconnect from the Nutanix cluster
#increment the counter
++$myvarCounter
}#end foreach Nutanix cluster loop
#connect to vcenter now
foreach ($myvarvCenter in $myvarvCenterServers)
{
OutputLogData -category "INFO" -message "Connecting to vCenter server $myvarvCenter..."
if (!($myvarvCenterObject = Connect-VIServer $myvarvCenter))#make sure we connect to the vcenter server OK...
{#make sure we can connect to the vCenter server
$myvarerror = $error[0].Exception.Message
OutputLogData -category "ERROR" -message "$myvarerror"
return
}
else #...otherwise show the error message
{
OutputLogData -category "INFO" -message "Connected to vCenter server $myvarvCenter."
}#endelse
if ($myvarvCenterObject)
{
##################################
#main processing for vcenter here#
##################################
#######################
# PROCESS VMHOSTS
#let's match host IP addresses we got from the Nutanix clusters to VMHost objects in vCenter
$myvarNtnxC1_vmhosts = @() #this is where we will save the hostnames of the hosts which make up the first Nutanix cluster
$myvarNtnxC2_vmhosts = @() #this is where we will save the hostnames of the hosts which make up the second Nutanix cluster
OutputLogData -category "INFO" -message "Getting hosts registered in $myvarvCenter..."
$myvarVMHosts = Get-VMHost #get all the vmhosts registered in vCenter
foreach ($myvarVMHost in $myvarVMHosts) #let's look at each host and determine which is which
{
OutputLogData -category "INFO" -message "Retrieving vmk interfaces for $myvarVMHost..."
$myvarHostVmks = $myvarVMHost.NetworkInfo.VirtualNic #retrieve all vmk NICs for that host
foreach ($myvarHostVmk in $myvarHostVmks) #examine all VMKs
{
foreach ($myvarHostIP in $myvarNtnxC1_hosts) #compare to the host IP addresses we got from the Nutanix cluster 1
{
if ($myvarHostVmk.IP -eq $myvarHostIP.hypervisorAddress)
{
OutputLogData -category "INFO" -message "$myvarVMHost.Name is a host in $ntnx_cluster1..."
$myvarNtnxC1_vmhosts += $myvarVMHost#if we get a match, that vcenter host is in cluster 1
}
}#end foreacch IP C1 loop
foreach ($myvarHostIP in $myvarNtnxC2_hosts) #compare to the host IP addresses we got from the Nutanix cluster 2
{
if ($myvarHostVmk.IP -eq $myvarHostIP.hypervisorAddress)
{
OutputLogData -category "INFO" -message "$myvarVMHost.Name is a host in $ntnx_cluster2..."
$myvarNtnxC2_vmhosts += $myvarVMHost #if we get a match, that vcenter host is in cluster 2
}
}#end foreacch IP C2 loop
}#end foreach VMK loop
}#end foreach VMhost loop
#check all vmhosts are part of the same vSphere cluster
OutputLogData -category "INFO" -message "Checking that all hosts are part of the same compute cluster..."
$myvarvSphereCluster = $myvarNtnxC1_vmhosts[0] | Get-Cluster #we look at which cluster the first vmhost in cluster 1 belongs to.
$myvarvSphereClusterName = $myvarvSphereCluster.Name
$myvarvSphereClusterVMHosts = $myvarNtnxC1_vmhosts + $myvarNtnxC2_vmhosts #let's create an array with all vmhosts that should be in the compute cluster
#get existing DRS groups
$myvarDRSGroups = (get-cluster $myvarvSphereClusterName).ExtensionData.ConfigurationEx.group
#get existing DRS rules
$myvarClusterComputeResourceView = Get-View -ViewType ClusterComputeResource -Property Name, ConfigurationEx | where-object {$_.Name -eq $myvarvSphereClusterName}
$myvarClusterDRSRules = $myvarClusterComputeResourceView.ConfigurationEx.Rule
foreach ($myvarvSphereClusterVMHost in $myvarvSphereClusterVMHosts) #let's now lok at each vmhost and which cluster they belong to
{
$myvarVMHostCluster = $myvarvSphereClusterVMHost | Get-Cluster #which cluster does this host belong to?
if ($myvarVMHostCluster -ne $myvarvSphereCluster) #let's check if it's the same cluster as our first host
{
$myvarVMHostName = $myvarvSphereClusterVMHost.Name
$myvarVMHostClusterName = $myvarVMHostCluster.Name
OutputLogData -category "ERROR" -message "$myvarVMHostName belongs to vSphere cluster $myvarVMHostClusterName when it should be in $myvarvSphereClusterName..."
break #we'l stop right here since at least one vmhost is not in the right compute cluster
}
}#end foreach cluster vmhost loop
#check that vSphere cluster has HA and DRS enabled
OutputLogData -category "INFO" -message "Checking HA is enabled on $myvarvSphereClusterName..."
if ($myvarvSphereCluster.HaEnabled -ne $true) {OutputLogData -category "WARN" -message "HA is not enabled on $myvarvSphereClusterName!"}
OutputLogData -category "INFO" -message "Checking DRS is enabled on $myvarvSphereClusterName..."
if ($myvarvSphereCluster.DrsEnabled -ne $true)
{
OutputLogData -category "ERROR" -message "DRS is not enabled on $myvarvSphereClusterName!"
break #exit since DRS is not enabled
}
#check to see if the host group already exists
$myvarDRSHostGroups = $myvarDRSGroups |?{$_.host} #keep host groups
#CREATE DRS affinity groups for hosts in each nutanix cluster
$myvarNtnxC1_DRSHostGroupName = "DRS_HG_MA_" + $ntnx_cluster1
$myvarNtnxC2_DRSHostGroupName = "DRS_HG_MA_" + $ntnx_cluster2
#do we have an existing DRS host group for c1 already?
if ($myvarDRSHostGroups | Where-Object {$_.Name -eq $myvarNtnxC1_DRSHostGroupName})
{ #yes, so let's update it
OutputLogData -category "INFO" -message "Updating DRS Host Group $myvarNtnxC1_DRSHostGroupName on cluster $myvarvSphereCluster"
Update-DrsHostGroup -cluster $myvarvSphereCluster -Hosts $myvarNtnxC1_vmhosts -groupHostName $myvarNtnxC1_DRSHostGroupName
}
else
{ #no, so let's create it
OutputLogData -category "INFO" -message "Creating DRS Host Group $myvarNtnxC1_DRSHostGroupName on cluster $myvarvSphereClusterName for $ntnx_cluster1..."
$myvarNtnxC1_vmhosts | New-DrsHostGroup -Name $myvarNtnxC1_DRSHostGroupName -Cluster $myvarvSphereCluster
}
#do we have an existing DRS host group for c2 already?
if ($myvarDRSHostGroups | Where-Object {$_.Name -eq $myvarNtnxC2_DRSHostGroupName})
{ #yes, so let's update it
OutputLogData -category "INFO" -message "Updating DRS Host Group $myvarNtnxC2_DRSHostGroupName on cluster $myvarvSphereCluster"
Update-DrsHostGroup -cluster $myvarvSphereCluster -Hosts $myvarNtnxC2_vmhosts -groupHostName $myvarNtnxC2_DRSHostGroupName
}
else
{ #no, so let's create it
OutputLogData -category "INFO" -message "Creating DRS Host Group $myvarNtnxC2_DRSHostGroupName on cluster $myvarvSphereClusterName for $ntnx_cluster2..."
$myvarNtnxC2_vmhosts | New-DrsHostGroup -Name $myvarNtnxC2_DRSHostGroupName -Cluster $myvarvSphereCluster
}
#######################
# PROCESS VMS and RULES
#check existing vm groups
$myvarDRSVMGroups = $myvarDRSGroups |?{$_.vm} #keep vm groups
#retrieve names of VMs in each active datastore
$myvarNtnxC1_vms, $myvarNtnxC2_vms = @()
##########################################################
#Process VM DRS Groups and DRS Rules for Nutanix cluster 1
foreach ($myvarDatastore in $myvarNtnxC1_MaActiveCtrs)
{
OutputLogData -category "INFO" -message "Getting VMs in datastore $myvarDatastore..."
$myvarNtnxC1_vms += Get-Datastore -Name $myvarDatastore | Get-VM
$myvarDRSVMGroupName = "DRS_VM_MA_" + $myvarDatastore
#compare. if not exist then create
if (!($myvarDRSVMGroups | Where-Object {$_.Name -eq $myvarDRSVMGroupName})) #the DRS VM Group does not exist, so let's create it
{
OutputLogData -category "INFO" -message "Creating DRS VM Group $myvarDRSVMGroupName on cluster $myvarvSphereClusterName for datastore $myvarDatastore which is active on $ntnx_cluster1..."
$myvarNtnxC1_vms | New-DrsVMGroup -Name $myvarDRSVMGroupName -Cluster $myvarvSphereCluster
}
else
{
#else edit existing
OutputLogData -category "INFO" -message "Updating DRS VM Group $myvarDRSVMGroupName on cluster $myvarvSphereClusterName for datastore $myvarDatastore which is active on $ntnx_cluster1..."
Update-DrsVMGroup -cluster $myvarvSphereCluster -VMs $myvarNtnxC1_vms -groupVMName $myvarDRSVMGroupName
}
#retrieve DRS rule
$myvarDRSRuleName = "DRS_Rule_MA_" + $myvarDatastore
#if not exist create
if (!($myvarClusterDRSRules | Where-Object {$_.Name -eq $myvarDRSRuleName})) #the DRS VM Group does not exist, so let's create it
{
#create DRS affinity rules for VMs to Hosts
OutputLogData -category "INFO" -message "Creating DRS rule $myvarDRSRuleName on cluster $myvarvSphereCluster so that VMs in $myvarDRSVMGroupName should run on hosts in $myvarNtnxC1_DRSHostGroupName..."
New-DrsVMToHostRule -VMGroup $myvarDRSVMGroupName -HostGroup $myvarNtnxC1_DRSHostGroupName -Name $myvarDRSRuleName -Cluster $myvarvSphereCluster
}
else #the DRS rule is already there
{
if (!($noruleupdate))
{
OutputLogData -category "INFO" -message "Updating DRS rule $myvarDRSRuleName on cluster $myvarvSphereCluster for $myvarDatastore..."
Update-DRSVMToHostRule -VMGroup $myvarDRSVMGroupName -HostGroup $myvarNtnxC1_DRSHostGroupName -Name $myvarDRSRuleName -Cluster $myvarvSphereCluster -RuleKey $(($myvarClusterDRSRules | Where-Object {$_.Name -eq $myvarDRSRuleName}).Key) -RuleUuid $(($myvarClusterDRSRules | Where-Object {$_.Name -eq $myvarDRSRuleName}).RuleUuid)
}
}
}#end foreach datastore in C1 loop
##########################################################
#Process VM DRS Groups and DRS Rules for Nutanix cluster 2
foreach ($myvarDatastore in $myvarNtnxC2_MaActiveCtrs)
{
OutputLogData -category "INFO" -message "Getting VMs in datastore $myvarDatastore..."
$myvarNtnxC2_vms += Get-Datastore -Name $myvarDatastore | Get-VM
$myvarDRSVMGroupName = "DRS_VM_MA_" + $myvarDatastore
#compare. if not exist then create
if (!($myvarDRSVMGroups | Where-Object {$_.Name -eq $myvarDRSVMGroupName}))
{
OutputLogData -category "INFO" -message "Creating DRS VM Group $myvarDRSVMGroupName on cluster $myvarvSphereClusterName for datastore $myvarDatastore which is active on $ntnx_cluster2..."
$myvarNtnxC2_vms | New-DrsVMGroup -Name $myvarDRSVMGroupName -Cluster $myvarvSphereCluster
}
else #else edit existing
{
OutputLogData -category "INFO" -message "Updating DRS VM Group $myvarDRSVMGroupName on cluster $myvarvSphereClusterName for datastore $myvarDatastore which is active on $ntnx_cluster2..."
Update-DrsVMGroup -cluster $myvarvSphereCluster -VMs $myvarNtnxC2_vms -groupVMName $myvarDRSVMGroupName
}
$myvarDRSRuleName = "DRS_Rule_MA_" + $myvarDatastore
#retrieve DRS rule
#if not exist create
if (!($myvarClusterDRSRules | Where-Object {$_.Name -eq $myvarDRSRuleName}))
{
#create DRS affinity rules for VMs to Hosts
OutputLogData -category "INFO" -message "Creating DRS rule $myvarDRSVMGroupName on cluster $myvarvSphereClusterName so that VMs in $myvarDRSVMGroupName should run on hosts in $myvarNtnxC2_DRSHostGroupName..."
New-DrsVMToHostRule -VMGroup $myvarDRSVMGroupName -HostGroup $myvarNtnxC2_DRSHostGroupName -Name $myvarDRSRuleName -Cluster $myvarvSphereCluster
}
else #the DRS rule is already there
{
if (!($noruleupdate))
{
OutputLogData -category "INFO" -message "Updating DRS rule $myvarDRSVMGroupName on cluster $myvarvSphereClusterName for $myvarDatastore..."
Update-DRSVMToHostRule -VMGroup $myvarDRSVMGroupName -HostGroup $myvarNtnxC2_DRSHostGroupName -Name $myvarDRSRuleName -Cluster $myvarvSphereCluster -RuleKey $(($myvarClusterDRSRules | Where-Object {$_.Name -eq $myvarDRSRuleName}).Key) -RuleUuid $(($myvarClusterDRSRules | Where-Object {$_.Name -eq $myvarDRSRuleName}).RuleUuid)
}
}
}#end foreach datastore in C2 loop
}#endif
OutputLogData -category "INFO" -message "Disconnecting from vCenter server $vcenter..."
Disconnect-viserver -Confirm:$False #cleanup after ourselves and disconnect from vcenter
}#end foreach vCenter
#########################
## cleanup ##
#########################
#let's figure out how much time this all took
OutputLogData -category "SUM" -message "total processing time: $($myvarElapsedTime.Elapsed.ToString())"
#cleanup after ourselves and delete all custom variables
Remove-Variable myvar*
Remove-Variable ErrorActionPreference
Remove-Variable help
Remove-Variable history
Remove-Variable log
Remove-Variable ntnx_cluster1
Remove-Variable ntnx_cluster2
Remove-Variable username
Remove-Variable password
Remove-Variable vcenter
Remove-Variable debugme
Configuring Sync DR
A few caveats for Sync DR:
- You won’t need DRS rules since your compute cluster isn’t stretched.
- When you create the Sync DR PD, make sure the container is empty and not mounted on the target site as vSphere may write stuff on it. Once the PD is online and ready, mount the countainer on all the hosts at the target site.
- If you do not complete the PD creation for any reason, you may end up with an empty Async DR PD definition in Prism. Delete it and start over after fixing whatever prevented you from creating it in the first place.
- Because the replicated container is mounted and visible on the target site, there is always the possibility that some admins will provision VMs to that container which will be registered on the target site. This should be avoided as it complicates matters when failing over and back. I will not be covering some of those advanced scenarios due to lack of time and resources, so I encourage you to review them in the Prism guide.
In part 2, we will see how to do planned failover for each type of protection domains on VMware vSphere.



I cant find part 2 and 3? have they not been posted yet?
Hello Stephane, This is a great series – thanks alot for you this very valuable information!!! I have a somewhat more complex setup…could you have a look at it? I have 2 datacenters 1 and 2 with two zones A and B each. In all 4 zones are Nutanix deployments. In both datacenters zones A should be replicated synchronously to zones B. In addition datacenter 1 should be relplicated asychronously to datacenter 2. My assumptions are: – There should be 4 Nutanix clusters; one in each zone – On top of the Nutanix deployments there should be 2 VMware HA… Read more »